A naive approach to identify financial risk in the online gambling industry
The gambling industry is one of the biggest entertainment industry in the world. Perhaps, one of the oldest as well. We can broadly classify it into sports betting, poker and casino which includes bingo, live game etc. It is currently a multi-billion industry and is estimated to grow further in the coming years.
Some facts and estimates on gambling industry:

Gambling regulation
The government regulate the legal gambling activities within a country. They provide licence to the companies and also enforces compliance and regulation standards to operate lawfully in this business. Institutions like the Financial Action Task Force (FATF) issues recommendations that serve as the international standard for financial transactions. Hence, any company must abide by these rules to successfully operate in this area.
Even with these strict laws, the risk to businesses is increasing with the growth of the industry. The introduction of multiple payment methods including wallets and bitcoins adds more stress in maintaining these rules. The older methods of manual account reviews aren’t sufficient to capture the risks on time. Moreover, any fraudulent or money-laundering activity damages the business by making the product unsafe for all the customers. For instance, a dishonest action in online Poker can cost money to other fair customers. Any such action incurs penalties from the authorities followed by loss of business reputation.
Financial risks
We can define financial risk into two categories, Fraud and Money-laundering activity. Fraud is any transaction made on an account that does not involve authorised credentials. It also includes actions which abuse bonuses or welcome offers of say, free spins. Another case is depositing using a stolen card or disowning high-value bets as accidental. “My cat walked on the keyboard.”
In money-laundering cases, customers hide the source/sink of their funds. It also includes fund cleaning like placing bets on low odds and claiming the winning as their source of income. Also, multiple transactions using various cards to shuffle funds using the casino as a medium.
The gambling industry’s financial risks are different than those of other financial institution because of the nature of the business. For instance, banks maintain a lot more customer data than possible by any gambling company. There is also no event of betting/gaming between deposits, withdrawals or any other transaction with banks. In this piece, we will explain the challenges, a simple yet effective solution and discuss it’s pros and cons.
Objective
With the large volume of transactional data collected by the gaming company on consumer behaviour,
How can we successfully identify a fraudulent or money-laundering event using machine learning? OR in other words,
Can we build a risk profile of an account towards the business?
Challenges
-
Unavailability of sufficient positive labelled data points. This situation leads to inefficient supervised ML models due to class imbalance problem. Additionally, the data points don’t provide coverage on all potential risks.
-
Business models like VIP customers. Gambling companies treat customers with high staking and depositing behaviour as VIP. (these accounts are extensively reviewed and verified for valid documentation and source of income). These VIPs and other potential accounts influence population statistics needed for an evaluation. For instance, the average deposit amount of the product or average bets per day.
-
Limitations imposed by different markets (country) due to currency, data availability and the rules set by the gambling commission. Such as different deposit limit for an unverified account in different countries. This proves to be tricky for a unified solution.
Solution
Given these challenges, it is reasonable to assume that consumer behaviour follows the same pattern. This is conceivable because,
- Customers typically have a fixed budget to spend in a said period. Say, a monthly deposit.
- Normally people follow a limited number of sports that restrains their gambling habits.
If we observe this pattern for each customer, we can identify any recent unusual activity as an anomaly. This assumption holds as a fundamental principle behind our solution, condition monitoring.
The general notion of this solution is to monitor the current conditions/features of each account by comparing it with their historical data. The account history can be aggregated over multiple time windows to generate total or average values. The time frame is usually governed by the business requirements. The table below shows some example of time windows used in this model
| Time window | Description |
|---|---|
| 24 hours | The last 24-hour transactions |
| 14 days | 14 days data before the last 24-hour |
| 3 months | 3-month data before the last 24-hour |
| Lifetime | Lifetime data before the last 24-hour |
Steps:
- Aggregate feature over different time windows. For e.g. total deposit amount over 14 days period.
- Compute averages for each feature and time period. For e.g. total deposit amount in 14 days / total number of deposits in 14 days. This results in deposit per day for the 14 day period.
- Compare the recent activity against the average aggregated values for different time windows.
- Highlight the difference as an anomaly flag using a pre-defined threshold.
The threshold value can be considered as the hyper-parameter of this model. For simplicity, we have used a hard partition of current (24-hour) value being greater than the averages.
Model
Let’s assume X is a set of all features from 1 to n. And, W is a set of all time windows from 0 to w. Then, for a single feature x
x0 : Current period value
xi : Aggregate of x over ith window
Hence, we defined a function f(x) such that
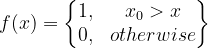
The anomaly score of a feature is given by
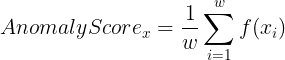
Therefore, the anomaly score for an account can be calculated as
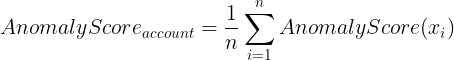
Features
| Features | Description |
|---|---|
| deposit_amount | The deposit amount in EUR |
| n_deposits | The number of successful deposits |
| wtd_amount | Withdrawal amount in EUR |
| n_wtds | Number of successful Withdrawal |
| stakes | The betting amount in EUR |
| n_bets | The number of bets placed |
| n_active_days | Total number of days customer was active on the product to place bets or play games |
| n_deposit_days | Total number of days customer made a deposit |
| n_wtd_days | Total number of days customer made a withdrawal |
This notebook demonstrate the implementation using deposit and withdrawal amount.
Pros and cons:
Pros
- Easy implementation. This solution can entirely be implemented in SQL and executed on-demand.
- Scalability. It evaluates all accounts registered for a product which complements the existing manual process of account reviews.
- The same solution can be implemented for different products in the business such as casino, sportsbook etc. Usually, the staking amount on sportsbook bets is higher than casino games. Hence, this solution limits the evaluation within the product behaviour.
- This model evaluates much larger historical data that can be rather tedious if done manually.
Cons
- High false-positive rate. The stringent comparison logic leaves very less margin for any deviation. Hence, flagging true on many features. Also, the lack of non-transactional data such as verified account status or payment source contributes to this effect.
- New customers are flagged high-risk due to nonexisting historical data for comparisons.
- Manual account reviews require background and documentation check which is not possible with this model.
Improvements and other possibilities
This model provides improved evaluation strategy for all accounts in a product. It incorporates all features that follow the moving average principle. However, there is a lot of scope for improvement.
- Generate individual score for each segment like payment transactions, casino gameplay, sportsbook etc. to highlight the reason for the anomaly flag.
- A better scoring technique like z-score (as explained in this post) or weighted average can enhance local anomaly detection.
- Use of better aggregation strategies. In this model, we have used transactions aggregated on per day basis e.g. deposit_24_hours. Based on the business requirement, one can explore the average per transaction. For example, the average deposit amount per transaction in the last 14 days.
- Embrace non-transactional features into the model. Such as, payment method risk level or KYC status as a boolean or numeric value.
- Implementing better algorithms like random cut forest algorithm, isolation forest anomaly detection or autoencoders etc. Features from this model can serve as an input to these solutions.
Summary
In this blog, we have first outlined how financial risk in the gambling industry is different from other financial institutions. Then, we studied a simple yet effective technique to detect anomaly in customer behaviour using moving averages method. This solution works on historical data and takes customer behaviour into account during evaluation. We have then listed some improvements over the current implementation that employs practical and superior techniques.
References
- Results on Page 1 of Google search for anomaly detection. I have read a lot of content while researching this solution. Hence, I would like to acknowledge everyone’s contribution on this topic. :)
I would also like to thank Ivan Ukhov for the inspiration to write and his feedback that made this blog a bit bearable. ;)